

After the previous blog post on setting up a Discord Bot and implementing Gemini to the bot, in this blog post, we will be focusing on the implementing of RAG to the bot.
To follow through the code here.
RAG and LangChain
RAG (retrieval augmented generation), is a model that combines the best of both worlds of retrieval and generation models. It is a model that can be used for open-domain question answering. The RAG model retrieves information relevant to a user’s query from a large dataset and then generates a detailed response based on this information.
LangChain is a framework for developing applications powered by language models. It enables applications that: Are context-aware: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.) Reason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)
This framework consists of several parts.
LangChain Libraries: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.
LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks.
LangServe: A library for deploying LangChain chains as a REST API.
LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
In this article, we will be building the RAG model on GCP using Vertex AI and Matching Engine, and then we will be integrating the model with the Discord Bot.
Here is a high level architecture of the RAG model and its implementation on GCP and Discord Bot. The diagram was initially published by Google, I added our application bits to the diagram.
Code Implementation
1 - Update pyproject.toml file
We will have to add the necessary dependencies for RAG implementation to the pyproject.toml file, which includes langchain and tensor. The dependencies are listed below.
langchain = "0.1.4"
langchain-google-vertexai = "^0.0.3"
langchain-google-genai = "^0.0.6"
protobuf = "^3.19.3"
and run
poetry update
2 - code implementation for production
Import the necessary libraries
import vertexai
from langchain.chains import RetrievalQA
from langchain_community.embeddings import VertexAIEmbeddings
from langchain_google_vertexai import VertexAI
from langchain.prompts import PromptTemplate
Depending on your GCP project quotas for different services and your needs, you can adjust the requests rate limit:
class CustomVertexAIEmbeddings(VertexAIEmbeddings):
requests_per_minute: int
num_instances_per_batch: int
@staticmethod
def rate_limit(max_per_minute):
period = 60 / max_per_minute
print("Waiting")
while True:
before = time.time()
yield
after = time.time()
elapsed = after - before
sleep_time = max(0, period - elapsed)
if sleep_time > 0:
print(".", end="")
time.sleep(sleep_time)
# Overriding embed_documents method
def embed_documents(
self, texts: List[str], batch_size: int = 0
) -> List[List[float]]:
limiter = self.rate_limit(self.requests_per_minute)
results = []
docs = list(texts)
while docs:
head, docs = (
docs[: self.num_instances_per_batch],
docs[self.num_instances_per_batch :],
)
chunk = self.client.get_embeddings(head)
results.extend(chunk)
next(limiter)
return [r.values for r in results]
Defining embedding, matching engine and retriever
For matching engine’s search type, there are similarity, mmr and similarity_score_threshold, in this example, we will be using similarity search.
class QuestionAnsweringSystem:
def __init__(self):
vertexai.init(project=self.PROJECT_ID, location=self.REGION)
self.embeddings = CustomVertexAIEmbeddings(
model_name="textembedding-gecko@001",
requests_per_minute=self.EMBEDDING_QPM,
num_instances_per_batch=self.EMBEDDING_NUM_BATCH,
)
self.mengine = MatchingEngineUtils(
self.PROJECT_ID, self.ME_REGION, self.ME_INDEX_NAME
)
self.me = MatchingEngine.from_components(
project_id=self.PROJECT_ID,
region=self.ME_REGION,
gcs_bucket_name=f"gs://{self.ME_EMBEDDING_DIR}".split("/")[2],
embedding=self.embeddings,
index_id=self.ME_INDEX_ID,
endpoint_id=self.ME_INDEX_ENDPOINT_ID,
)
self.retriever = self.me.as_retriever(
search_type="similarity",
search_kwargs={
"k": self.NUMBER_OF_RESULTS,
"search_distance": self.SEARCH_DISTANCE_THRESHOLD,
},
)
Defining our LLM model to generate the response, we will be using Gemini as our LLM model.
temperature: This parameter controls the randomness of the model’s predictions. A higher value makes the output more random, while a lower value makes it more deterministic. For example, with a high temperature, the model might generate more creative or diverse responses, while with a low temperature, it’s more likely to generate the most probable response.
top_k: During text generation, the model calculates probabilities for the next token (word/part of a word) and selects from the top_k most likely tokens. A higher top_k allows more diversity but also more chance of irrelevant or incorrect responses, while a lower top_k restricts the model to choose from a smaller set of most likely tokens, leading to more focused but less diverse responses.
top_p (also known as nucleus sampling): Instead of selecting from the top_k most likely tokens, the model selects from the smallest set of tokens whose cumulative probability exceeds top_p. This can lead to more dynamic selection of tokens compared to top_k. For instance, if top_p=0.9, the model will select the next token from a set of top probable tokens that together make up 90% of the total probability.
The max_output_tokens parameter specifies the maximum number of tokens in the generated text. A token can be a word or part of a word, depending on the language and the specific tokenization method used by the model.
To define a llm model - Gemini example
from langchain_google_vertexai import VertexAI
llm = VertexAI(
model_name="gemini-pro",
max_output_tokens=8100,
temperature=0.2,
top_p=0.8,
top_k=40,
verbose=True,
)
To define a llm model - GPT example
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
deployment_name=f"{gpt_model_name}",
azure_endpoint=f"https://api-endpoint.com",
api_key=token_response.json()["access_token"],
api_version=f"{api_version}",
model_kwargs=dict(
user=f'{{"appkey": "{OPENAI_API_KEY}"}}'
),
)
Defining the Retrieval QA
qa = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
verbose=True,
chain_type_kwargs={
"prompt": PromptTemplate(
template=prompt.RAG_PROMPT,
input_variables=["context", "question"],
),
},
)
Finally, we will be defining the function that will be used to generate the response, if the response is not found in the context, we will be using Gemini to generate the response.
def ask(self, query, k=None, search_distance=None) -> str:
if k is None:
k = self.NUMBER_OF_RESULTS
if search_distance is None:
search_distance = self.SEARCH_DISTANCE_THRESHOLD
self.qa.retriever.search_kwargs["search_distance"] = search_distance
self.qa.retriever.search_kwargs["k"] = k
result = self.qa.invoke({"query": query})
output_result = self.formatter(result)
if any(word in result["result"].split() for word in self.rag_nores_list):
result = gcpaiapi.get_response(
query, response_type="gem", use_existing_session=False
)
output_result = (
f"The provided context does not contain information about the question, retrieving answer directly from Gemini.\n\n"
f"\n**Gemini Response**"
f"\n\n\n{result}"
)
return output_result
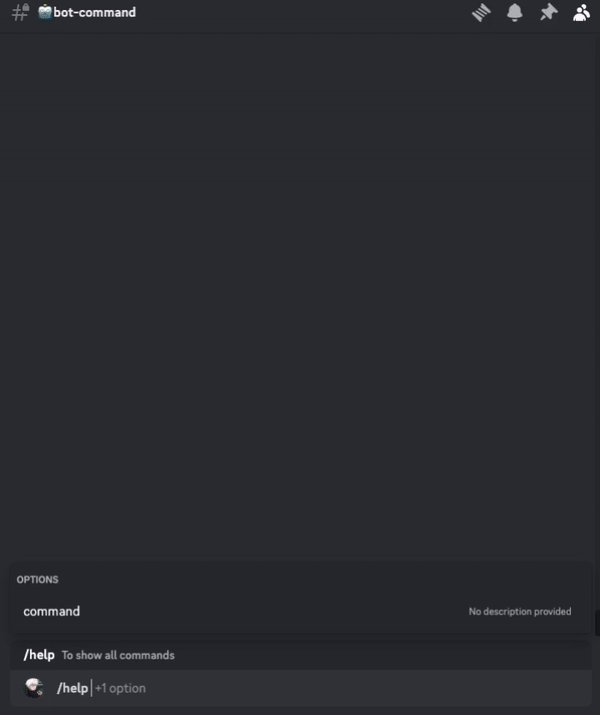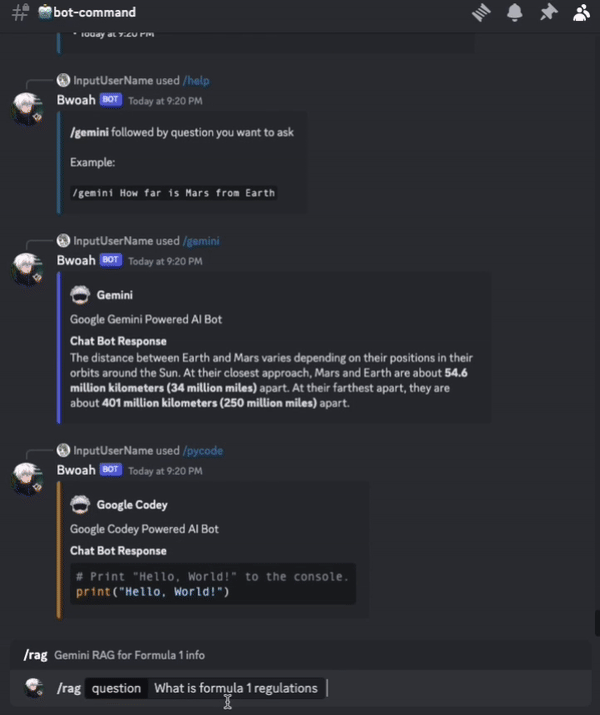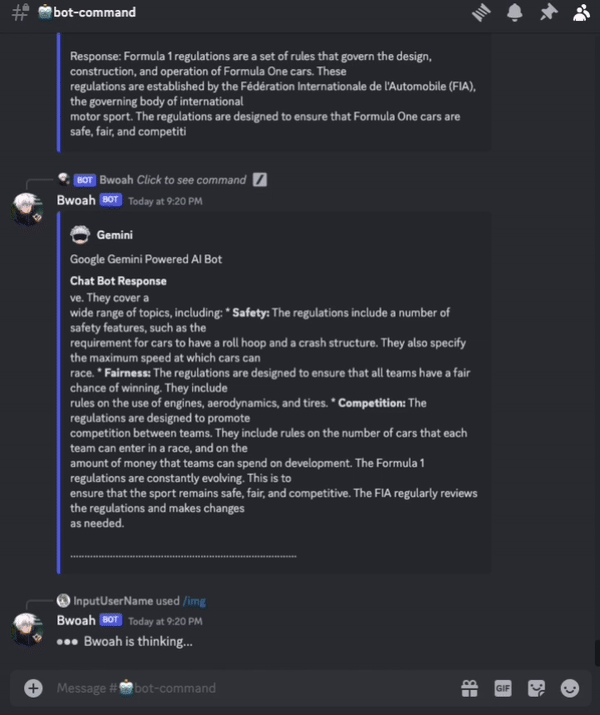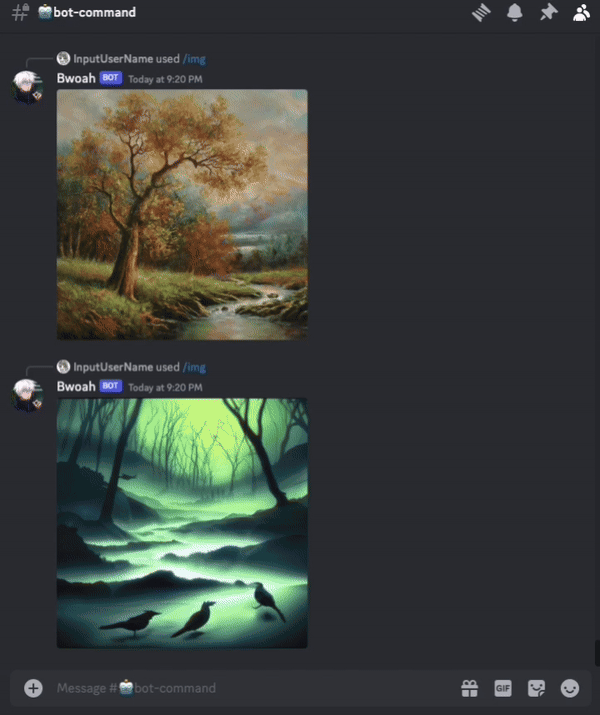
And that’s it! We now have a Discord chat bot that can answer questions based on the context provided.
Here is the result:
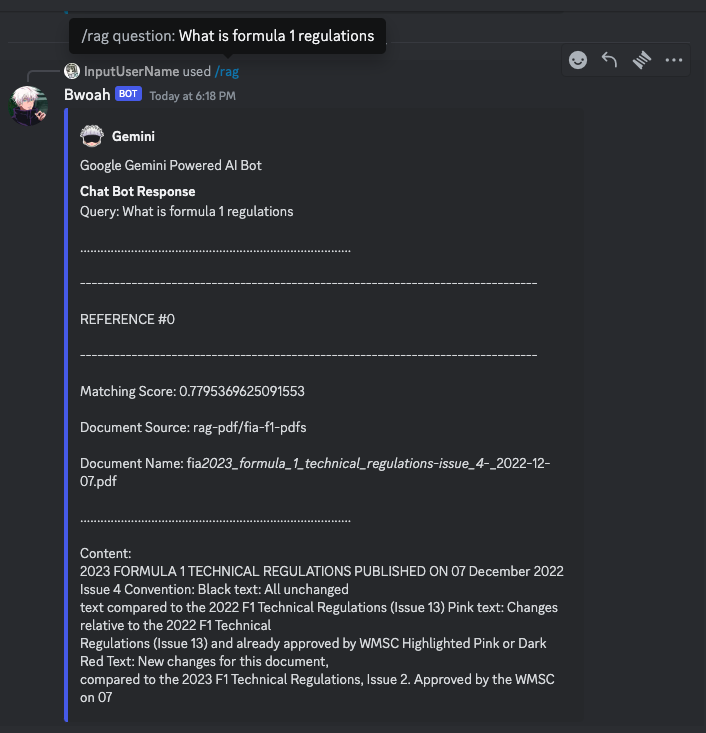
Thank you for reading and have a nice day!

