

Introduction
In my previous articles, we have talked about how to set up a Cloud Run application with for MLFlow Server and Kubflow on GKE with Ingress, load balancer, IAP set up for only allowing traffic from specific IP addresses. In this article, I will talk about how to deploy ML endpoints to serve predictions as a Cloud Run applications with Ingress control to communicate with each other, also how to deploy a Vertex AI serving endpoint and a kubeflow KServe endpoint.
Architecture
Here is an overview of the MLOPS workflow.
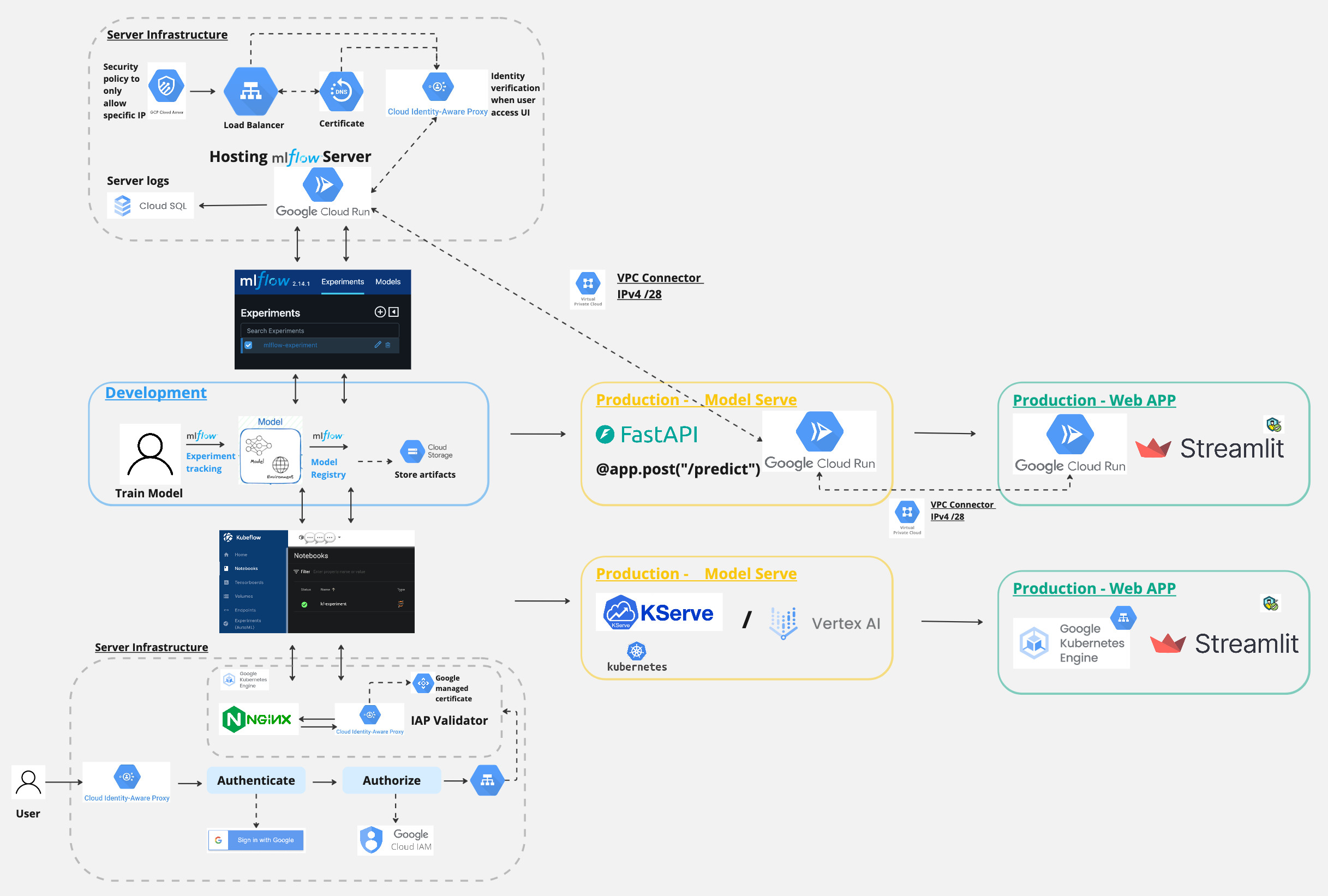
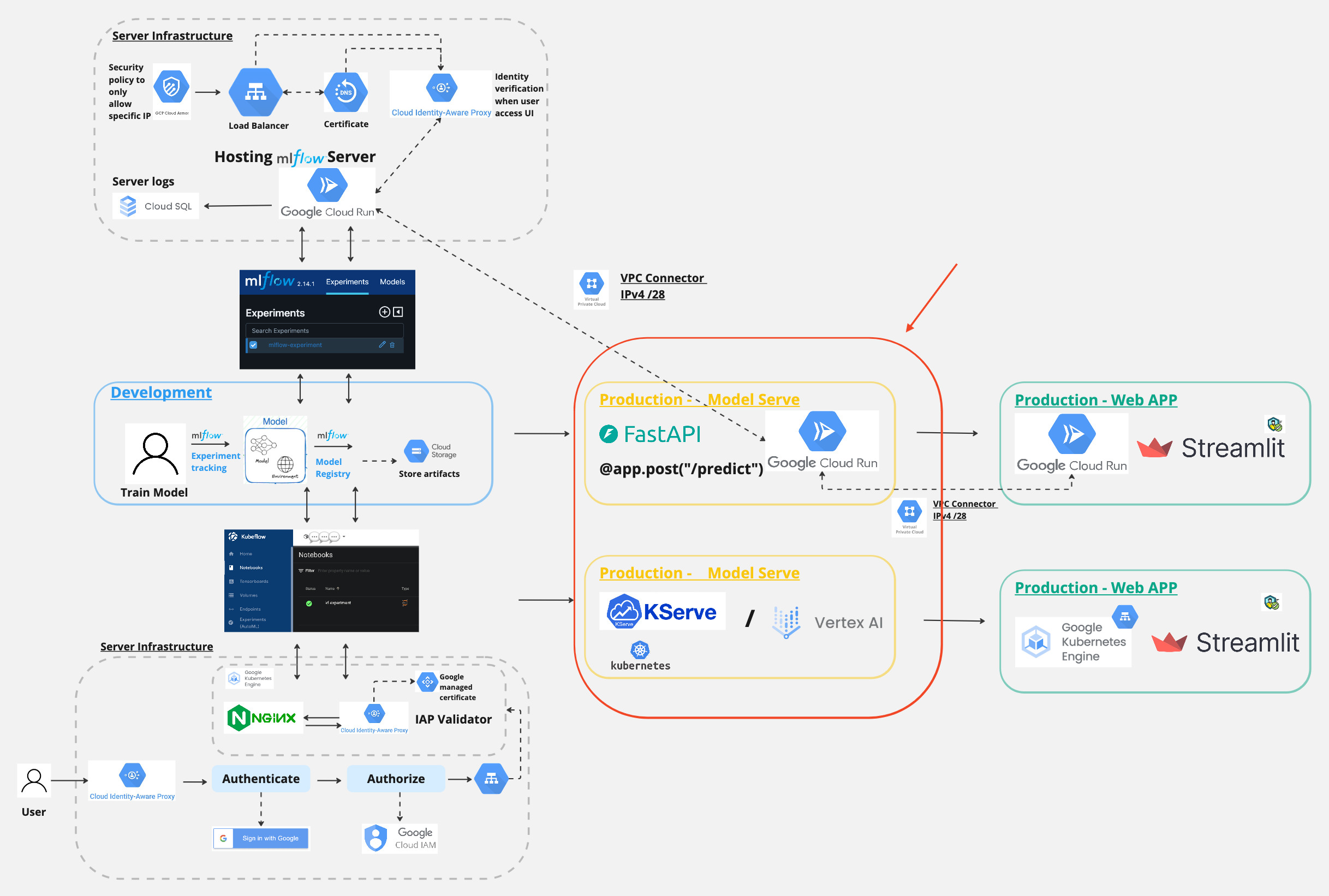
And in today’s post, we will focus on this part.
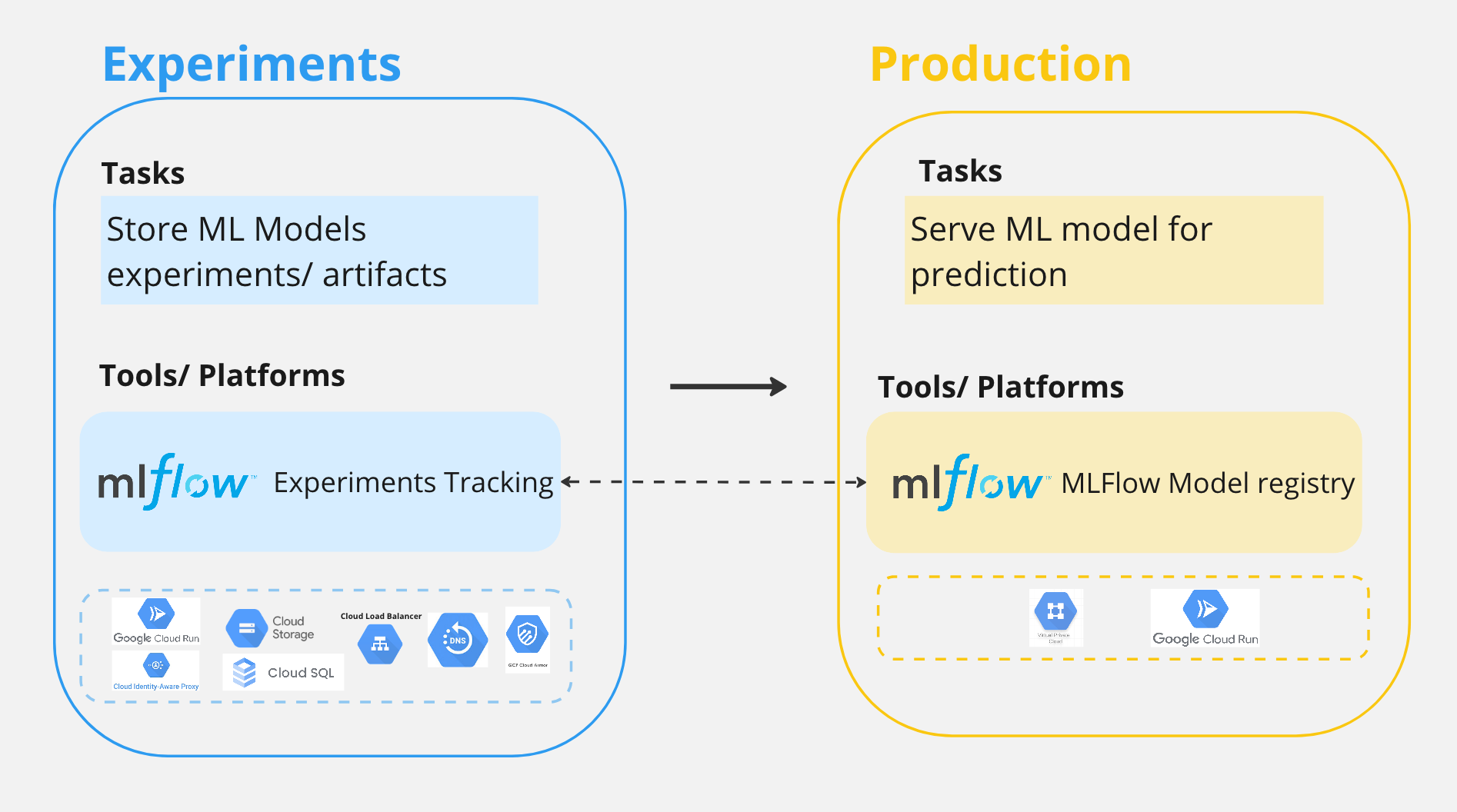
To follow along this blog post, the repo is here
Learnings
In today’s post, we will be
1 - Set up a VPC connector for the Cloud Run application
2 - Create a FastAPI application that uses MLFlow model to make predictions
3 - Deploy Cloud Run applications with appropriate configuration
4 - Make a request to the FastAPI application to make predictions
5 - Set up a Vertex AI endpoint (optional)
6 - Set up a Kubeflow KServe endpoint (optional)
Set Up VPC connector
The reason for setting up Cloud Run applications with Ingress control to communicate with each other is that after setting up MLFlow with Cloud Run application, we will be building an API endpoint that uses model from MLFlow to make predictions. We will deploy the API endpoint with Cloud Run as the second application, thus the two applications need to communicate with each other. With the MLFlow application set up with Ingress, if we set up the API endpoint without any network control, it will not be able to reach the MLFlow API to retrieve the model for making predictions. Therefore, we will set up a VPC connector for the API endpoint to communicate with the MLFlow application.
A high level application structure looks something like this
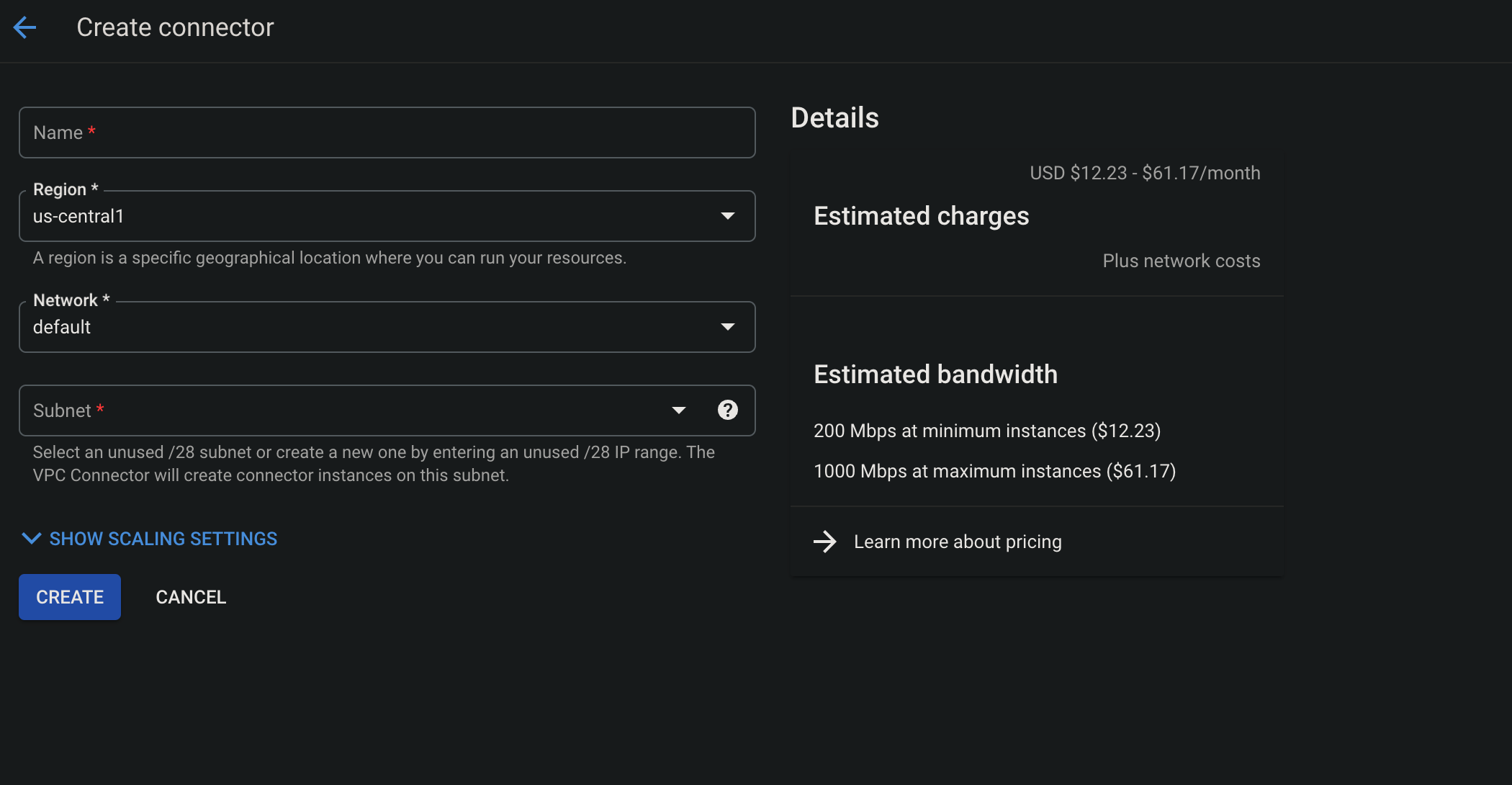
To create a VPC connector, on GCP console, we can navigate to VPC network -> Serverless VPC access -> Create connector, fill in the necessary details and create the connector.
To check the available locations for VPC connector, we can run the following command
gcloud compute networks vpc-access locations list
Create FastAPI application
Folder strcutre for the FastAPI application looks like this
.
├── Dockerfile
├── README.md
├── app
│ ├── basic_auth.py
│ ├── gcp_secrets.py
│ ├── helpers
│ │ ├── load_mlflow_models.py
│ │ └── models.py
│ ├── main.py
│ └── settings.py
├── deploy
│ └── production
│ └── service.yaml
├── poetry.lock
├── pyproject.toml
└── skaffold.yaml
Our Dockerfile looks like this, please note that the python version that we are using for the API endpoint needs to be the same as the environment where the prediction API will be used. For example, if you will be calling the API from a Jupiter notebook, the python version of the Jupiter notebook should also e 3.11
FROM python:3.11-slim
WORKDIR /usr/src/app
ENV PYTHONUNBUFFERED=1 \
PYTHONDONTWRITEBYTECODE=1 \
POETRY_VERSION=1.7.1 \
USERNAME=nonroot
RUN adduser $USERNAME
USER $USERNAME
ENV HOME=/home/$USERNAME
ENV PATH="$HOME/.local/bin:$PATH"
RUN pip install pipx
RUN pipx install poetry==${POETRY_VERSION}
COPY ./poetry.lock pyproject.toml /usr/src/app/
RUN poetry install -nv --no-root
COPY app .
CMD ["poetry", "run", "uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
Our pyproject.toml looks like this. Same as Dockerfile, apart from the python version, the scikit-learn and xgboost version should be the same as the environment where the prediction API will be used. Could be a Jupiter notebook, a local python virtual env, etc.
[tool.poetry]
name = "mlflow-wine-pred-endpoint"
version = "0.1.0"
description = ""
authors = [""]
readme = "README.md"
[tool.poetry.dependencies]
python = "3.11"
pandas = "2.2.2"
httpx = "^0.27.0"
fastapi = "^0.104.1"
uvicorn = "^0.24.0.post1"
emoji = "^2.9.0"
pydantic-settings = "^2.2.1"
mlflow = "2.14.1"
xgboost = "1.7.5"
scikit-learn = "1.3.1"
google-cloud-secret-manager = "^2.16.3"
google-cloud-logging = "^3.8.0"
google-cloud-storage = "^2.10.0"
requests = "^2.31.0"
[build-system]
requires = ["poetry-core>=1.4.1"]
build-backend = "poetry.core.masonry.api"
For the API endpoint, we will want to set up a mechanism to authenticate the request to the API endpoint. We can use HTTPBasic for this. The validate function will be used to validate the credentials. The validate function will be used as a dependency for the API endpoint.
import secrets
from typing import Annotated
from fastapi import Depends, HTTPException
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from settings import app_config
security = HTTPBasic()
AUTH_USERNAME = app_config.MLFLOW_TRACKING_USERNAME.encode("utf8")
AUTH_PASSWORD = app_config.MLFLOW_TRACKING_PASSWORD.encode("utf8")
def validate(credentials: Annotated[HTTPBasicCredentials, Depends(security)]):
current_username_bytes = credentials.username.encode("utf8")
is_correct_username = secrets.compare_digest(current_username_bytes, AUTH_USERNAME)
current_password_bytes = credentials.password.encode("utf8")
is_correct_password = secrets.compare_digest(current_password_bytes, AUTH_PASSWORD)
if not (is_correct_username and is_correct_password):
raise HTTPException(status_code=401)
return credentials.username
And in our main.py, we can set up the API endpoint like this. Which ensures that the request to the API endpoint is authenticated.
from fastapi import Depends, FastAPI, Response, Request, HTTPException
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
from fastapi.security import HTTPBasicCredentials
from typing import List, Annotated
import pandas as pd
from helpers.models import WineQualityInput
from helpers.load_mlflow_models import load_latest_model
from basic_auth import validate
from os import getenv
import google.cloud.logging
import logging
if (env := getenv("ENV")) and env == "prod":
client = google.cloud.logging.Client()
client.setup_logging()
logging.basicConfig(
level=logging.INFO,
format="[%(asctime)s] {%(filename)s:%(lineno)d} %(name)s - %(message)s",
)
logger = logging.getLogger(__name__)
app = FastAPI()
@app.get("/health")
async def health():
return "ok"
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request: Request, exc: RequestValidationError):
exc_str = f"{exc}".replace("\n", " ").replace(" ", " ")
logger.error(f"{request}: {exc_str}")
content = {"code": 422, "message": exc_str, "data": None}
return JSONResponse(content=content, status_code=422)
@app.post("/invocations")
async def invocations(
inputs: List[WineQualityInput],
credentials: Annotated[HTTPBasicCredentials, Depends(validate)],
):
input_df = pd.DataFrame([input_data.dict() for input_data in inputs])
model = load_latest_model()
try:
predictions = model.predict(input_df)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
return predictions.tolist()
Deploy Cloud Run application with VPC connector
Deploy FastAPI application to Cloud Run using skaffold
The skaffold.yaml looks like this
apiVersion: skaffold/v4beta2
kind: Config
metadata:
name: mlflow-wine-pred-endpoint-app
build:
artifacts:
- image: us-central1-docker.pkg.dev/gcp-prj-id-123/mlflow-gcp/mlflow-wine-pred-endpoint-app
docker:
dockerfile: Dockerfile
platforms:
- "linux/amd64"
profiles:
- name: production
manifests:
rawYaml:
- deploy/production/service.yaml
deploy:
cloudrun:
projectid: gcp-prj-id-123
region: us-central1
We can see the skaffold configuration file is set up to reference deploy/production/service.yaml.
The service.yaml file looks like this
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: mlflow-wine-pred-endpoint-app
labels:
cloud.googleapis.com/location: us-central1
annotations:
spec:
template:
metadata:
annotations:
run.googleapis.com/vpc-access-egress: all-traffic
run.googleapis.com/vpc-access-connector: projects/gcp-prj-id-123/locations/us-central1/connectors/custom-vpc-connector
spec:
serviceAccountName: svc@developer.gserviceaccount.com
containers:
- image: us-central1-docker.pkg.dev/gcp-prj-id-123/mlflow-gcp/mlflow-wine-pred-endpoint-app
ports:
- name: http1
containerPort: 80
env:
- name: GCP_PROJECT_ID
value: gcp-prj-id-123
- name: ENV
value: prod
We can see we have set the run.googleapis.com/vpc-access-egress and run.googleapis.com/vpc-access-connector annotations to allow the Cloud Run application to use the VPC connector we have created.
And finally, to deploy, we can run the command
skaffold run -p production
Redeploy MLFlow application to use VPC
Update the deploy/production/service.yaml to add the below lines under spec -> template -> metadata -> annotations
run.googleapis.com/vpc-access-egress: private-ranges-only
run.googleapis.com/vpc-access-connector: projects/gcp-prj-id-123/locations/us-central1/connectors/custom-vpc-connector
The complete yaml file looks like this
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: mlflow-gcp
annotations:
run.googleapis.com/ingress: internal-and-cloud-load-balancing
run.googleapis.com/ingress-status: internal-and-cloud-load-balancing
spec:
template:
metadata:
annotations:
run.googleapis.com/cloudsql-instances: gcp-prj-id-123:us-central1:gcp-pgsql
run.googleapis.com/startup-cpu-boost: 'true'
run.googleapis.com/vpc-access-egress: private-ranges-only
run.googleapis.com/vpc-access-connector: projects/gcp-prj-id-123/locations/us-central1/connectors/custom-vpc-connector
spec:
serviceAccountName: svc@developer.gserviceaccount.com
containers:
- image: us-central1-docker.pkg.dev/gcp-prj-id-123/mlflow-gcp/mlflow-gcp
ports:
- name: http1
containerPort: 8080
env:
- name: GCP_PROJECT
value: gcp-prj-id-123
resources:
limits:
memory: 2Gi
cpu: 1000m
To deploy
skaffold run -p production
Make a request to the FastAPI application to make predictions
from google.cloud import secretmanager
class GCPSecrets:
def __init__(self) -> None:
self.client = secretmanager.SecretManagerServiceClient()
self.base_url = f"projects/{PROJECT_ID}/secrets"
def get_secret(self, secret):
secret_response = self.client.access_secret_version(
name=f"{self.base_url}/{secret}/versions/latest"
)
creds = secret_response.payload.data.decode("UTF-8")
return creds
secrets = GCPSecrets()
import base64
import requests
import json
cred_str = f"{secrets.get_secret("user")}:{secrets.get_secret("password")}"
cred_bytes = str.encode(cred_str)
credentials = base64.b64encode(cred_bytes).decode("utf-8")
headers = {
"Content-Type": "application/json",
"Authorization": f"Basic {credentials}",
}
# Prepare the input data
input_data = X_test.to_dict(orient='records')
input_data = input_data[:5]
input_json = json.dumps(input_data)
CLOUD_RUN_URL = f"{secrets.get_secret("prediction-endpoint")}/invocations"
# Make a request to the FastAPI application to make predictions
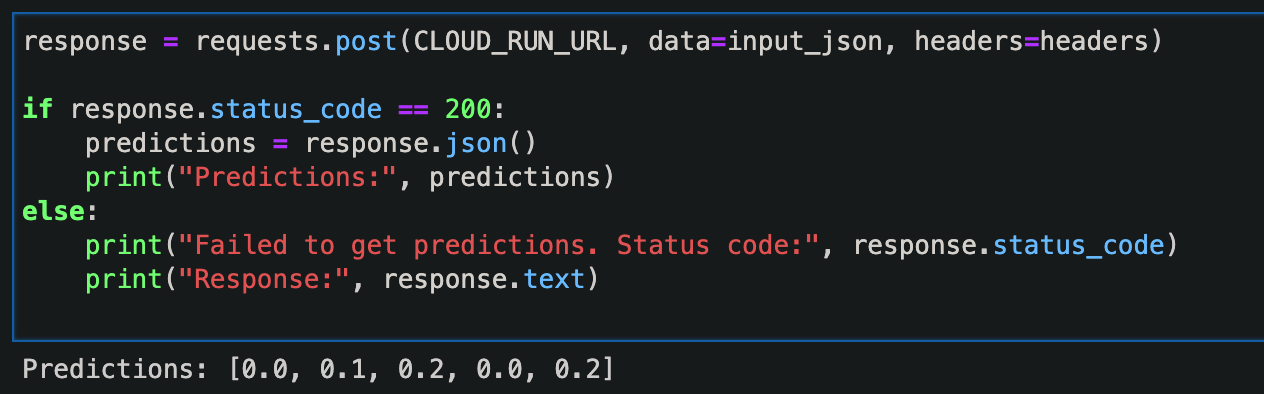
response = requests.post(CLOUD_RUN_URL, data=input_json, headers=headers)
if response.status_code == 200:
predictions = response.json()
print("Predictions:", predictions)
else:
print("Failed to get predictions. Status code:", response.status_code)
print("Response:", response.text)
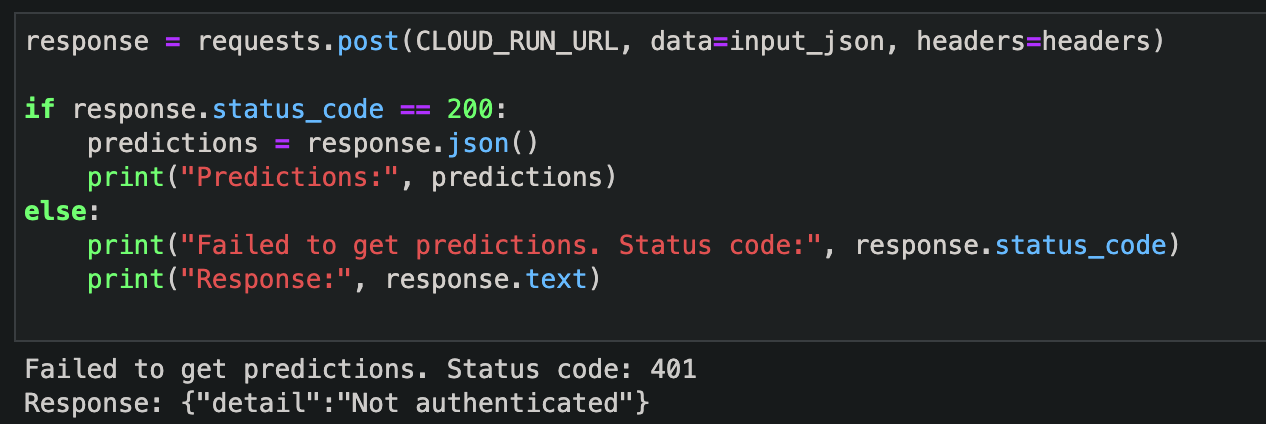
And then if we try to request the FastAPI application to make predictions, without an Authentication header, we will get an error like this
Set Up Vertex AI endpoint (optional)
We already slightly discussed about this on the previous post, to use kubeflow to deploy a Vertex AI servin endpoint, we can execute the below.
@component(
packages_to_install=["google-cloud-aiplatform"]
)
def model_deployment()-> NamedTuple("endpoint", [("endpoint", str)]):
from google.cloud import aiplatform
aiplatform.init(project="gcp-prj-id-123", location="us-central1", staging_bucket="gs://gcp-bucket-kubeflow")
model = aiplatform.Model.upload(
display_name="coupon-recommendation-model",
artifact_uri="gs://gcp-bucket-kubeflow/ml-model/artifacts/",
serving_container_image_uri = "us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-6:latest",
sync=False
)
DEPLOYED_NAME = "coupon-model-endpoint"
TRAFFIC_SPLIT = {"0": 100}
MIN_NODES = 1
MAX_NODES = 1
endpoint = model.deploy(
deployed_model_display_name=DEPLOYED_NAME,
traffic_split=TRAFFIC_SPLIT,
machine_type="n1-standard-4",
min_replica_count=MIN_NODES,
max_replica_count=MAX_NODES
)
@dsl.pipeline(
pipeline_root="gs://gcp-bcuket-kubeflow/ml-pipeline-v1",
name="ml-model-training-ep-deplyment-pipeline",
)
def pipeline(
project: str = "kubeflow-mlops",
region: str = "us-central1"
):
max_depth=5
learning_rate=0.2
n_estimators=40
input_validation_task = validate_input_ds()
model_training = custom_training_job_component(
max_depth=max_depth,
learning_rate=learning_rate,
n_estimators=n_estimators,
).after(input_validation_task)
with dsl.Condition(model_training.outputs["model_validation"] == "true"):
task_deploy_model = model_deployment().after(model_training)
compiler.Compiler().compile(pipeline_func=pipeline,package_path='ml-pipeline-ep-deploy.json')
start_pipeline = pipeline_jobs.PipelineJob(
display_name="ml-model-ep-deployment-pipeline",
template_path="ml-pipeline-ep-deploy.json",
enable_caching=False,
location="us-central1",
)
start_pipeline.run()
Set Up KServe endpoint (optional)
To deploy the endpoint to Kserve
# Import the necessary libraries
from kubernetes import client
from kserve import KServeClient
from kserve import constants
from kserve import utils
from kserve import V1beta1InferenceService
from kserve import V1beta1InferenceServiceSpec
from kserve import V1beta1PredictorSpec
from kserve import V1beta1XGBoostSpec
namespace = utils.get_default_target_namespace()
name = 'xgboost-ml-model'
kserve_version = 'v1beta1'
api_version = constants.KSERVE_GROUP + '/' + kserve_version
# Define InferenceService
isvc = V1beta1InferenceService(api_version=api_version,
kind=constants.KSERVE_KIND,
metadata=client.V1ObjectMeta(
name=name, namespace=namespace, annotations={'sidecar.istio.io/inject': 'false'}),
spec=V1beta1InferenceServiceSpec(
predictor=V1beta1PredictorSpec(
xgboost=V1beta1XGBoostSpec(
storage_uri="gs://gcp-bucket-kubeflow/ml-model/artifacts/",
)
)
)
)
# Create InferenceService
KServe = KServeClient()
KServe.create(isvc)
Thank you for reading and have a nice day!

