

After our last blog post on setting up Airflow, in this blog post, we will be focusing on the implementation of our DAGs.
So here are the two DAGs we will be implementing:
- DAG 1: This DAG will be responsible for scraping the news data from the different website and storing it in the GCS bucket then send the new news to a Discord channel via webhook.
- DAG 2: This DAG will be responsible for scraping the standing data from the Formula 1 website and storing it in the GCS bucket then send the new standing to Google BigQuery.
Code Implementation
1 - Folder Structure looks something like this
├───dags
│ │
│ ├───project_1
│ │ dag_1.py
│ │ dag_2.py
│ │
│ └───project_2
│ dag_1.py
│ dag_2.py
│
├───plugins
│ ├───hooks
│ │ pysftp_hook.py
| | servicenow_hook.py
│ │
│ ├───sensors
│ │ ftp_sensor.py
| | sql_sensor.py
| |
│ ├───operators
│ │ servicenow_to_azure_blob_operator.py
│ │ postgres_templated_operator.py
│ |
│ ├───scripts
│ ├───project_1
| | transform_cases.py
| | common.py
│ ├───project_2
| | transform_surveys.py
| | common.py
│ ├───common
| helper.py
| dataset_writer.py
2 - DAGs Definition
DAG 1 - Pushing News to Discord As shown below, the DAG will be triggered every hour at 5 minutes past the hour. The DAG will be responsible for scraping the news data from the different website and storing it in the GCS bucket then send the new news to a Discord channel via webhook.
The function is responsible for reading the previous news from the GCS bucket, comparing it with the current news, and publishing the new news to the Discord channel via webhook. The function also writes the current news to the GCS bucket.
def publish_news(news_data: list, file_name: str, newsoutlet_name: str, wh_url: str):
msg_published = 0
data = news_data
prev_news = read_prev_news(file_name)
print(f"Previos News read from bucket:\n{prev_news}")
for i in range(0, len(data), 2):
print(i)
if data[i] not in prev_news:
message_to_webhook(newsoutlet_name, data[i], data[i + 1], wh_url)
msg_published += 1
if "bbc" in file_name:
write_data = process_data(data)
write_news(file_name, write_data)
else:
write_news(file_name, data)
print(f"Current news write to bucket:\n{data}")
print(
f"Published {msg_published} {newsoutlet_name} to webhook\nNews write to text file"
)
Then we can define the DAG as follows:
with DAG(
dag_id="news_push_dc_dag",
default_args={
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
},
description="A simple news publishing DAG",
schedule_interval="5 * * * *",
start_date=datetime(2024, 1, 7),
catchup=False,
tags=["discord_news"],
) as dag:
publish_bbc_football_task = PythonOperator(
task_id="publish_bbc_football_news",
python_callable=discordapi.publish_news,
op_kwargs={
"news_data": news.get_bbc_sport_news(
"https://www.bbc.co.uk/sport/football"
),
"file_name": "bbc_pl",
"newsoutlet_name": "BBC PL News",
"wh_url": SPORTS_WH,
},
dag=dag,
)
publish_bbc_f1_task = PythonOperator(
task_id="publish_bbc_f1_news",
python_callable=discordapi.publish_news,
op_kwargs={
"news_data": news.get_bbc_sport_news(
"https://www.bbc.co.uk/sport/formula1"
),
"file_name": "bbc_f1",
"newsoutlet_name": "BBC Formula 1 News",
"wh_url": SPORTS_WH,
},
dag=dag,
)
publish_f1_task = PythonOperator(
task_id="publish_f1_official_news",
python_callable=discordapi.publish_news,
op_kwargs={
"news_data": news.get_f1_official_news(),
"file_name": "officialf1",
"newsoutlet_name": "Official F1 News",
"wh_url": SPORTS_WH,
},
trigger_rule=TriggerRule.ALL_DONE,
dag=dag,
)
publish_nyt_tech_task = PythonOperator(
task_id="publish_nyt_tech_news",
python_callable=discordapi.publish_news,
op_kwargs={
"news_data": news.get_nyt_tech_news(),
"file_name": "nyt_tech",
"newsoutlet_name": "NYT Tech News",
"wh_url": TECH_WH,
},
trigger_rule=TriggerRule.ALL_DONE,
dag=dag,
)
publish_bbc_football_task >> publish_bbc_f1_task >> publish_f1_task >> publish_nyt_tech_task
DAG 2 - Pushing Formula 1 Standing to BigQuery
As shown below, the DAG will be triggered every Sunday at 11pm. The DAG will be responsible for scraping the standing data from the Formula 1 website and storing it in the GCS bucket then send the new standing to Google BigQuery.
The code is responsible for reading and writing data to GCS bucket. One thing to note is that, instead of using gcsfs for reading and writing files, we are using the storage. As gcsfs might be easier to use to cases like cloud functions, but it requires more configuration to work with Airflow.
class GCPStorages:
def __init__(self) -> None:
self.client = storage.Client()
self.fs = gcsfs.GCSFileSystem(project=GCP_PROJECT)
def get_gcs_bucket(self, bucket_name: str) -> storage.Bucket:
return self.client.bucket(bucket_name)
def read_csv(self, bucket_name: str, gcs_file_path: str) -> pd.DataFrame:
bucket = self.get_gcs_bucket(bucket_name)
blob = bucket.blob(gcs_file_path)
csv_content = BytesIO()
blob.download_to_file(csv_content)
csv_content.seek(0)
return pd.read_csv(csv_content)
def write_csv(self, bucket_name: str, gcs_file_path: str, dataframe: pd.DataFrame):
bucket = self.get_gcs_bucket(bucket_name)
csv_data: IO = BytesIO()
dataframe.to_csv(csv_data, index=False)
csv_data.seek(0)
# Upload the CSV string to GCS
blob = bucket.blob(gcs_file_path)
blob.upload_from_file(csv_data, content_type="text/csv")
And below is the code for ingesting data to BigQuery.
class GCPBQ:
def __init__(self) -> None:
self.client = bigquery.Client()
self.base_url = f"gs://gcs-airflow/gcp-bq"
def ingest_bq(
self,
file_path: str,
table_id: str,
write_disposition: str = "WRITE_APPEND",
source_format: str = "CSV",
) -> str:
job_config = bigquery.LoadJobConfig(
write_disposition=getattr(bigquery.WriteDisposition, write_disposition),
source_format=getattr(bigquery.SourceFormat, source_format),
skip_leading_rows=1,
)
load_job = self.client.load_table_from_uri(
f"{self.base_url}/{file_path}",
f"{GCP_PROJECT}.{table_id}",
job_config=job_config,
)
load_job.result()
return load_job.job_id
def read_data(self, query: str) -> pd.DataFrame:
query_job = self.client.query(query)
rows = query_job.result()
return rows.to_dataframe()
Then we can define the DAG as follows:
with DAG(
dag_id="f1_std_elt_dag",
default_args={
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
},
description="F1 Std Data ELT DAG",
schedule_interval="0 23 * * SUN",
start_date=datetime(2024, 1, 12),
catchup=False,
tags=["bq_elt"],
) as dag:
write_driver_std_to_storage_task = PythonOperator(
task_id="write_driver_std_to_storage",
python_callable=gcsapi.write_csv,
op_kwargs={
"bucket_name": "gcs-airflow",
"gcs_file_path": f"gcp-bq/driver_std_{datetime.today().strftime('%Y%m%d')}.csv",
"dataframe": f1api.get_driver_rank(),
},
dag=dag,
)
write_team_std_to_storage_task = PythonOperator(
task_id="write_team_std_to_storage",
python_callable=gcsapi.write_csv,
op_kwargs={
"bucket_name": "gcs-airflow",
"gcs_file_path": f"gcp-bq/team_std_{datetime.today().strftime('%Y%m%d')}.csv",
"dataframe": f1api.get_team_rank(),
},
dag=dag,
)
ingest_team_std_bq_task = PythonOperator(
task_id="ingest_team_std_bq",
python_callable=bqapi.ingest_bq,
op_kwargs={
"file_path": f"team_std_{datetime.today().strftime('%Y%m%d')}.csv",
"table_id": "formula1.team_std",
"write_disposition": "WRITE_APPEND",
},
dag=dag,
)
ingest_driver_std_bq_task = PythonOperator(
task_id="ingest_driver_std_bq",
python_callable=bqapi.ingest_bq,
op_kwargs={
"file_path": f"driver_std_{datetime.today().strftime('%Y%m%d')}.csv",
"table_id": "formula1.driver_std",
"write_disposition": "WRITE_APPEND",
},
dag=dag,
)
write_driver_std_to_storage_task >> write_team_std_to_storage_task >> ingest_team_std_bq_task >> ingest_driver_std_bq_task
Result
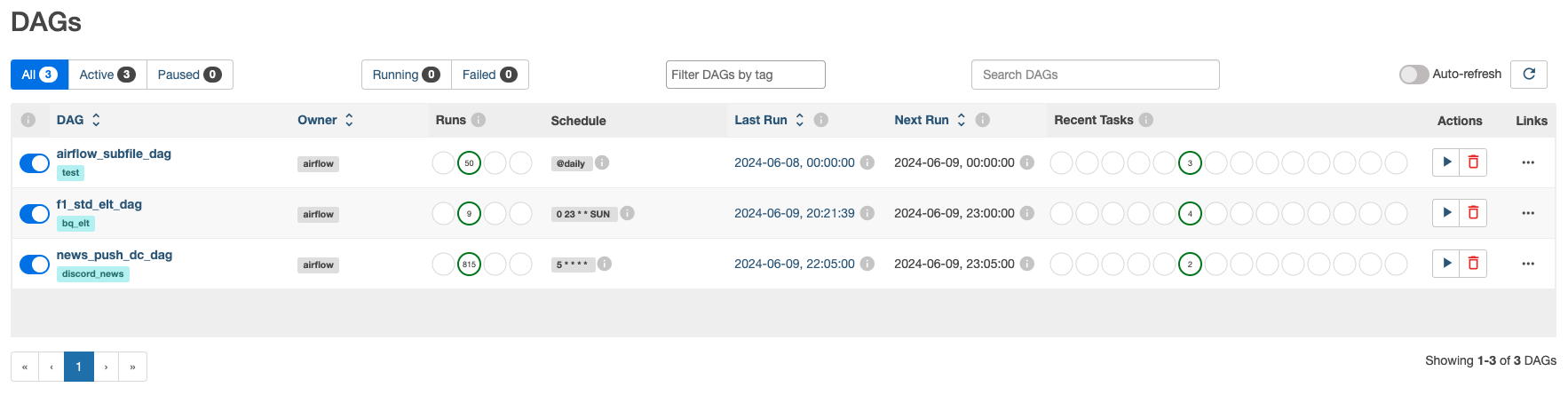
Let’s have a look at the result of the DAGs.
News are sending to Discord channel, and we can also verify our pipelines on the Airflow UI.

And that’s it, successful runs are showing on the UI, with logs stored in GCS bucket.
Thank you for reading and have a nice day!
